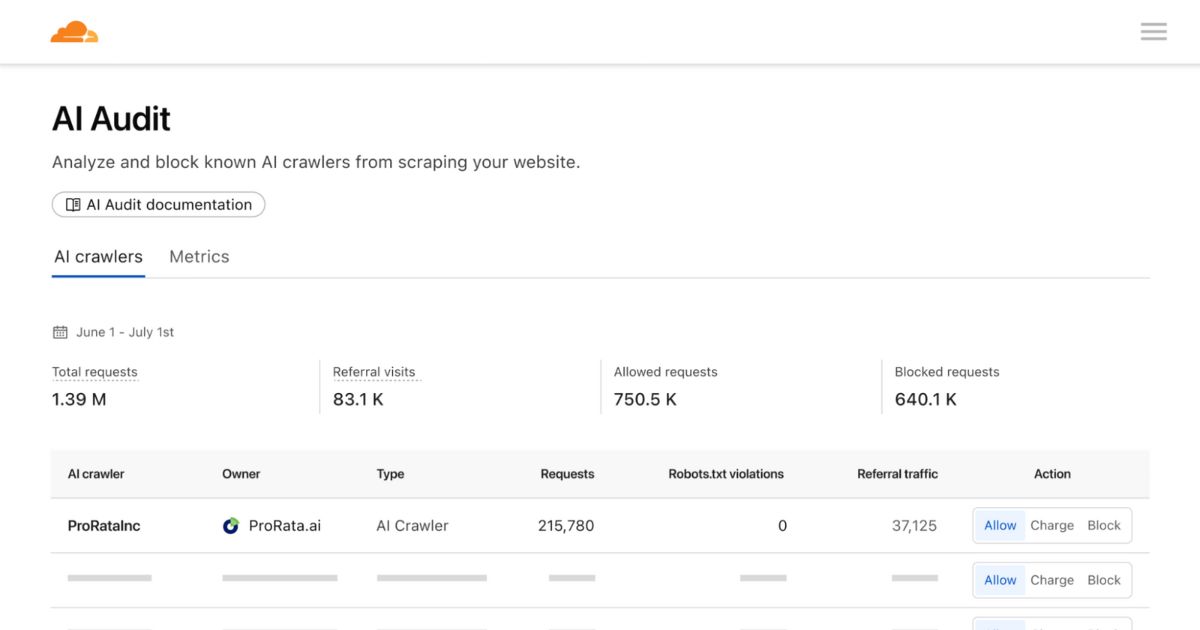
Cloudflare 宣布了一项名为“按次付费”的新功能,使网站所有者可以向 AI 爬虫收取访问其内容的费用。
这标志着 HTTP 响应代码 402 Payment Required(一项长期未使用的标准)的首次大规模实施,它使出版商和创作者能够更好地控制 AI 模型如何以及何时对其作品进行索引或训练。
什么是按次爬取付费?
如今,许多内容所有者面临着一个二元决策:完全阻止人工智能爬虫或允许它们免费无限制访问。 Cloudflare的新系统引入了第三种选择:使用内置的计费和验证机制按请求向爬虫收费。
通过按次付费爬取,内容所有者可以使用 Cloudflare 能够:
- 为AI爬虫充电 根据每个请求
- 阻止或允许 根据需要选择特定的爬虫
- 使用 基于规则的引擎 在现有机器人/WAF 策略之后控制定价和访问
该功能目前处于私人测试阶段,但标志着向更具货币化和基于许可的网络转变,特别是在生成性人工智能抓取的背景下。
运作模式
AI爬虫必须通过身份验证 Cloudflare 使用 Web Bot Auth 标准,一种使用签名的 HTTP 标头和公钥加密来验证爬虫身份的方法。
当爬虫访问内容时:
- 如果包含付款意图,则提供内容(HTTP 200 OK)。
- 如果没有,服务器将以 HTTP 402 Payment Required 进行响应,并附带价格。
- 发布者可以定义固定费率或绕过特定机器人的收费。
- 金融交易由 Cloudflare 作为记录商家。
这意味着,即使人工智能公司之前与出版商没有任何关系,现在也可以向其收取访问费用,或者通过邀请付费以编程方式阻止其访问。
我们的看法:更大的影响及其重要性
这是为了什么 Cloudflare?
据我们所知, Cloudflare 这不仅解决了出版商的痛点,还为可编程网络许可层奠定了基础,可以重塑人工智能、搜索甚至个人助理的经济状况。
从规模上看,按次付费爬取可以:
- 实现数百万个域名的数字内容定价标准化
- 为人工智能代理和抓取工具创建实时许可市场
- 让网站所有者选择性地将不同类型的内容(例如评论、研究、论坛)货币化
从长远来看,这个立场 Cloudflare 作为机器与内容交互的清算层,计费、身份和规则执行均在边缘处理。如果智能代理在用户使用网络的方式中占据主导地位(通过 Siri、 ChatGPT或垂直AI工具), Cloudflare 可能成为管理访问、合规性和货币化的默认收费站。
为什么它对托管和出版商如此重要
这一举措对于新闻编辑室、博客、论坛和托管评论网站尤其重要,例如 HostScore.net – 所有这些都产生了经常被人工智能模型抓取的高价值原创内容。
到目前为止,出版商和AI开发者之间的授权协议都是一次性的,难以扩展,而且只有大型媒体集团才能获得。“按次付费”模式允许任何域名所有者为爬虫程序设定价格,并有可能在AI系统使用其内容进行训练或推理时获得收益。
对于托管空间,它还提出了战略问题:
- 托管服务提供商是否应在其仪表板中支持按次付费爬取功能?
- 带宽或抓取限制会成为选择网络主机的一个因素吗?
- 可以定价 APIs 并且元数据模式如何发展以支持动态 AI 访问许可?
Cloudflare的实施可以为开放网络上更广泛的货币化标准奠定基础——不仅适用于人工智能训练,也适用于代表最终用户消费内容的未来代理应用程序。
谁可以使用 Cloudflare “按次付费”?
该功能目前处于私人测试阶段。 Cloudflare 邀请:
- AI爬虫运营商愿意为内容访问付费
- 想要收费访问的出版商和内容创作者
有兴趣者可以通过以下方式申请 cloudflare.com/paypercrawl-signup.