Cloudflare experienced a widespread service outage on November 18, 2025, beginning at approximately 11:20 UTC. The disruption affected a large portion of global internet traffic and caused service interruptions across major platforms, including ChatGPT, Claude, Spotify, X, and HostScore.net. The failure led to persistent HTTP 5xx errors, broken authentication flows, and heightened latency within Cloudflare’s network.
Cloudflare later confirmed that the incident was not caused by a cyber attack, despite early speculation due to the scale and symptoms of the failure. This announcement serves as an official update for our readers, partners, and stakeholders as we document what happened, how it spread, and how services eventually recovered.
Scope of the Disruption
The outage caused Cloudflare’s core CDN and security layers to stop processing traffic normally, leading to a sharp spike in HTTP 5xx errors across the network. Visitors to affected websites encountered error pages, stalled loads, or long delays as Cloudflare’s proxy layer struggled to respond. Key services including Bot Management, Turnstile, Workers KV, and Cloudflare Access degraded at the same time. The impact compounded on websites that relied on Cloudflare for caching, security, and authentication.
Cloudflare’s dashboard was also difficult to access because Turnstile, the verification layer on the login page, failed to load. The company’s externally hosted status page went offline as well, which created confusion during the early minutes of the incident. While Cloudflare’s email infrastructure continued to operate, spam detection accuracy briefly declined due to the loss of an IP reputation feed.
Root Cause: The Latent Bug
Cloudflare confirmed that the outage was triggered by a latent bug in a core component of its Bot Management system.
At 11:05 UTC, a routine database permission update unintentionally altered how the feature-generation service queried metadata. Instead of pulling from a single schema, the service began querying both the default and r0 schemas, producing a large set of duplicate feature rows. This bloated configuration file was then propagated across Cloudflare’s global network.
The core proxy engine enforces a hard limit of 200 machine-learning features for performance and memory allocation. The oversized file exceeded this limit, causing the FL2 proxy to panic and return 5xx errors for all affected requests. Customers still on the older FL engine did not fail outright, but their Bot Management scores defaulted to zero, leading to inconsistent traffic handling.
Resolution Timeline
Cloudflare detected the first wave of errors in customer traffic at 11:28 UTC.
Engineers initially focused on Workers KV, which showed an abnormal drop in response rates between 11:32 and 13:05 UTC.
At 13:04 UTC, Cloudflare applied an emergency patch to bypass the core proxy for Workers KV, followed by a similar bypass for Cloudflare Access at 13:05 UTC.
By 13:37 UTC, the engineering team began rolling back the Bot Management configuration to a known-good version.
Cloudflare halted the creation of new feature files at 14:24 UTC and deployed the corrected configuration globally at 14:30 UTC, which restored normal traffic flow.
Dashboard login issues cleared later, with full control-panel access restored around 15:30 UTC. Cloudflare marked the incident fully resolved at 17:06 UTC.
HostScore.net Impact Statement
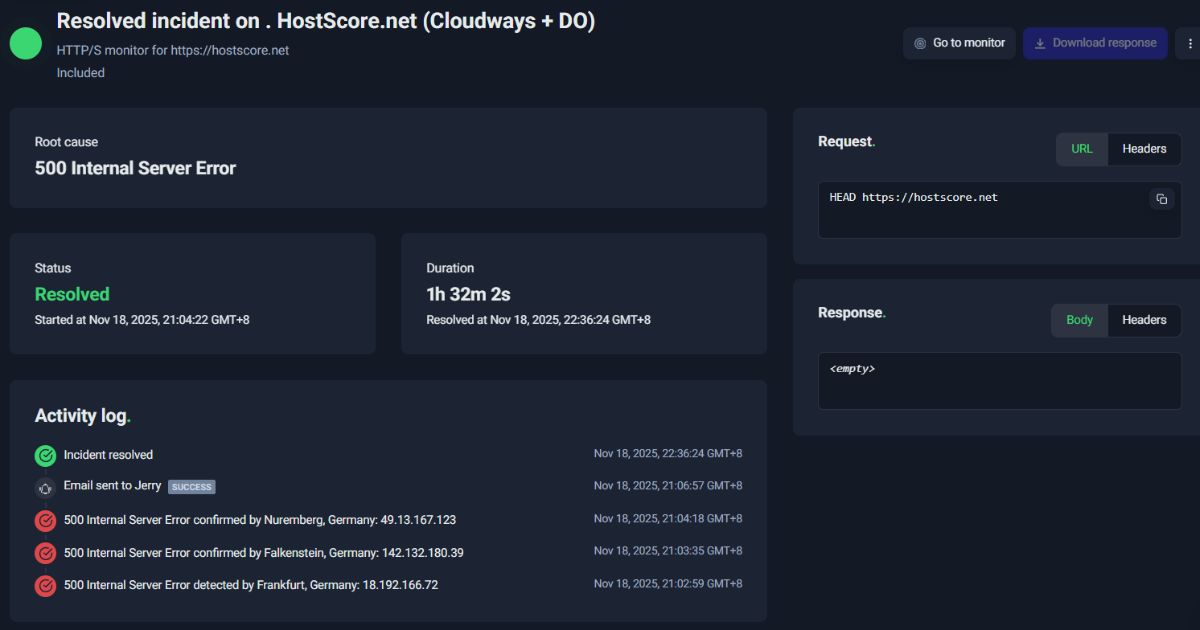
HostScore.net was among the sites affected during the outage window. Our team observed immediate spikes in 5xx responses and temporary unavailability as Cloudflare’s CDN and security layers failed to process requests. Site recovery occurred gradually as Cloudflare implemented its rollback and restoration steps.
Our monitoring systems detected the issue within minutes, and we continued tracking network behavior until full stability returned. While the outage originated upstream from our infrastructure, we remain committed to transparency and will continue improving our monitoring and contingency processes to strengthen overall service resilience.
Cloudflare’s Acknowledgment and Post-Incident Actions
Cloudflare publicly acknowledged the severity of the incident, with CTO Dane Knecht issuing an apology and stating that the company “failed its customers and the broader internet.” The company described the event as its most serious outage since 2019, underscoring how a small configuration error can cascade through large-scale distributed systems.
Cloudflare has begun work on several long-term improvements, including hardening the ingestion process for internally generated configuration files, expanding global kill switches to isolate faulty components more quickly, and preventing error-reporting surges from consuming system resources. With infrastructure spanning 330 cities and powering an estimated 20% of the web, Cloudflare emphasized its commitment to preventing similar failures in the future.
Wrapping Up
This incident highlights how much of today’s internet relies on a small number of foundational service providers. When one of these networks experiences a fault, the ripple effects can reach millions of users within minutes. As Cloudflare works on its remediation plan, HostScore.net remains committed to transparency, continuous monitoring, and ongoing improvements that strengthen the resilience of our platform and the reliability of the services our readers depend on.